Create publicly available web page archives with Archive.is
Web pages can change from one moment to the next. Entire websites may go down and take contents with them, content may be edited or removed, or sites may become unavailable because of technical issues.
If you need access to information, or want to save a copy of them to make sure you can access them at all time, then you have several options at your disposal to do so.
Probably the easiest is to save the web page to your local system. Hit Ctrl-s while on it, pick a descriptive name and local directory, and all of the contents are saved to the computer you are working on. Extensions like Mozilla Archive Format improve that further by saving all contents to a single file.
Another option is to take a screenshot of the page or part of it instead. This works as well, has the advantage that you save a single file but the disadvantage that you cannot copy text.
Tip: Firefox users hit Shift-F2, type screenshot and then enter to create a screenshot of the active web page. Chrome users can save web pages as PDF documents natively instead.
The third local option comes in the form of website archivers. Programs like Httrack crawl websites for you and save all contents to a local directory that you can then browse at anytime even without Internet connection.
Remote options can be useful as well. The most popular is without doubt offered by Archive.org as it creates automatic snapshots of popular Internet pages that you can access then. Want to see one of the first versions of Ghacks? Here you go.
The downside is that you cannot control what is saved.
Archive.is is a free service that helps you out. To use it, paste a web address into the form on the services main page and hit submit url afterwards.
The service takes two snapshots of that page at that point in time and makes it available publicly.
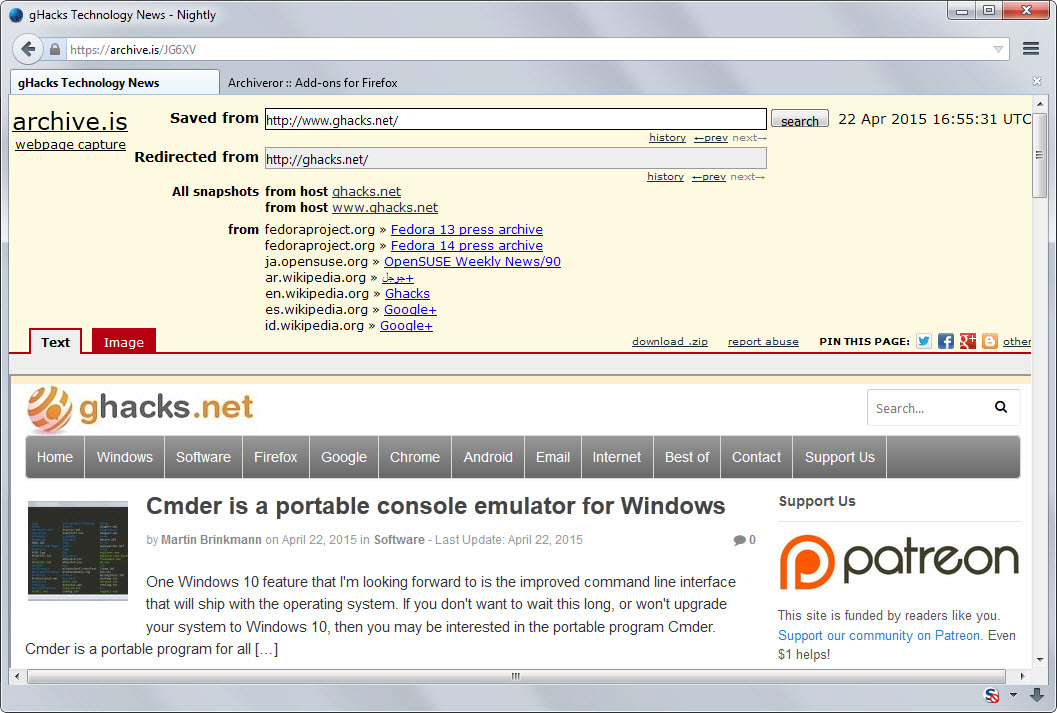
The first takes a static snapshot of the site. You find images, text and other static contents included while dynamic contents and scripts are not.
The second snapshot takes a screenshot of the page instead.
An option to download the data is provided. Note that this downloads the textual copy of the site only and not the screenshot.
A Firefox add-on has been created for the service which may be useful to some of its users. It creates automatic snapshots of every web page that you bookmark in the web browser after installation of the add-on.
Word of warning: All snapshots are publicly available. While pages that require authentication cannot be saved by the service, it may still take snapshots of pages that you may not want to reveal to the public.
An option to password protect snapshots or protect them using accounts would certainly be useful in this regard.
The service can prove useful in other situations. For instance, if you cannot access a resource on the Internet, then you may still access it by using Archive.is instead. While that provides access to text and image information only, it should be sufficient in most cases.
Closing Words
Archive.is is a useful but specialized service. It works well right out of the box but would benefit from protective features or an optional account system. All in all though, it can be quite handy at times to save web page information permanently in another location on the Internet.
This article was first seen on ComTek's "TekBits" Technology News

- Log in to post comments